Contents
Authentication and in particular passwords are the bugbear of many cybersecurity professionals. For all the encryption, firewalls, IDS and other defences we put in place, if authentication doesn’t do its job properly, or a user’s credentials get stolen, a compromise is very likely.
In the future, we might embrace password-less authentication, relying instead on biometrics, tokens and smart devices in various combinations. Indeed, some platforms do this already, but not all. Password’s aren’t going to disappear any time soon.
Is there more that we can do to keep passwords safe? While there are many weaknesses with using passwords, such as poorly chosen phrases, re-use across accounts, or post-its stuck to screens, today I want to focus on one critical issue:
- Users give up their credentials to untrustworthy servers (aka phishing)
This is particularly relevant in the month I’m posting this, because there’s been a lot of talk in Singapore and around the world about phishing scams targeting banking customers. It seems a single lapse in customer vigilance, without the right additional safeguards in place, can lead to bank accounts being emptied. As I’ve said previously in response to this spate of attacks:
We cannot expect humans to perform perfectly 100% of the time, so we should always design security to account for this.
In this article I’m going to explain channel binding, in particular over TLS, to see if it’s something that deserves more widespread support. Let’s take a closer look.
Phishing
It’s all too easy for a user to be duped into submitting their credentials to a site that’s impersonating a legitimate one. The phishing site may have a valid TLS certificate, secure connection, and even successfully login and redirect the user to the real site… after gathering all of the information it needs. If the user doesn’t notice that the domain isn’t quite right, they might never know how they got phished.
Fundamentally, phishing of this kind is a man-in-the-middle (MITM) attack. One that frequently happens over a seemingly secure channel. Users have been trained that a padlock symbol on their address bar means everything is A-OK.

The above diagram shows layers (based on no particular model) of the security present between a typical user and a web application, along with the knowledge, data, authentication factors and keys in each of their possession. Between them is an example of what security provision each layer can provide, although this is non-exhaustive.
In brief, certificates and roots of trust help the user to verify that the application represents the domain that they are connecting to (this bit is important as we’ll see later). The TLS session provides symmetric encryption and message integrity, usually through derivation of a key, hopefully with forward secrecy. The credential exchange layer allows client and server to mutually prove they know who the client is claiming to be (see the later section on SCRAM for more on this). A Time-based One-Time-Password (TOTP) allows the user to prove to the application that they are in possession of an additional authentication factor such as a token or TOTP app. Finally, the application session token can be used to prove that the previous authentication steps have been successfully completed, letting the app quickly determine the user and their authorisation status in future exchanges, for a while at least.
At the sides of the user and app are examples of attacks that could be mounted against the user or app at each layer. We’re not so interested in these attacks for this article, however. Instead, we will be inserting the attacker between the user and app.

Above is a diagram that shows how a MITM attack, leveraging phishing techniques, can overcome a number of the layers shown previously. First, we assume that the user follows a phishing link and fails to identify that the site is not on the correct domain. All other failures are technological, and are highlighted on the diagram in yellow/orange callout boxes, along with some successes in green.
Site legitimacy
The failures start at the lowest level, with the MITM presenting a valid certificate, but for the phishing domain, rather than the intended app domain (e.g. for eggsample.org instead of example.org). It’s impossible to expect a Certificate Authority to detect all phishing sites at the time of site verification and certificate signing, just like the average user will not spot a phishing link 100% of the time, so let’s not consider that a failure. As mentioned, the user fails to notice the wrong domain, but if they check the connection security, they will be falsely reassured by the valid TLS session that’s in place.
Turning our attention to the app, we see that the MITM can, if it wishes, verify the app, just like a client would. It might not bother, but it certainly could. This doesn’t help at all though, because the vast majority of TLS is one-way authentication, whereby only the server has to prove identity and authenticity. At this level, without mutual TLS, the app has no way to know that the client connection it is seeing comes from a MITM.
TLS
With the authenticity layer defeated, the next layer becomes broken too. There is no longer end-to-end encryption between the user and app, because two TLS sessions now exist, with their own (ironically secure) session keys and encryption schemes. The MITM can read all traffic sent to it, before securely forwarding it.
User authentication
Some good news is that the authentication scheme used by the app is reasonably good. A method such as SCRAM is used, meaning no plaintext passwords are sent, and both sides must prove suitable knowledge in order for successful authentication. Through the use of nonce-based challenges, the MITM cannot reuse this data, and thanks to salting and hashing of the exchanged data, it cannot easily reverse any credentials. Note that simpler authentication schemes such as HTTP Basic Authentication would be broken at this point. If you think basic authentication over TLS is safe, then think again.
Multi-factor
The good news continues, partially, at the next level. The MITM can obtain the OTP, but this will only be valid for a short while. They cannot predict what the next or indeed any future OTP will be, so the time window for an attack is narrow. Unfortunately, it’s not narrow enough…
By forwarding the OTP to the app, the app responds with a session token that it expects the user to provide for future communications. This will be the basis for proving that authentication has taken place and that the user is authorized to perform certain activities with the app. Alas, the MITM gets a look at this token, and while it may kindly provide it to the user so that they can continue to use the app, it may also use it for its own purposes, such as siphoning out user data, making purchases, misusing resources, etc.
The sum of failures
The problem in the case of this attack is that disclosure of the application session token is not dependent on an uninterrupted encrypted session between the user and app. In fact, assuming that mTLS is not an option and that the user or any other automated system cannot be relied upon to spot a phishing domain, three opportunities were still missed to stop this attack in its tracks: At the first authentication factor, then the second factor, and finally the session token exchange.
SCRAM
The Salted Challenge Response Authentication Mechanism, SCRAM, is something I want to cover before getting into TLS. not least because it was the way in which I first became aware of the idea of channel binding. I posted about SCRAM on LinkedIn in early 2021.
The idea behind SCRAM is that passphrases are used to generate hashes, which in turn are used to generate keys. Client and server do a little dance with these keys to prove that they both know the same passphrase, without ever having to utter the passphrase (or its first-stage hash) directly.
This approach is nice because it also helps the client to verify the server. A malicious server might accept any password in an attempt to phish for credentials. With SCRAM, such an approach is not possible. As such it’s got some extra safety built-in compared to basic HTTP authentication over a TLS connection, where you may be securely sending your plaintext password to… somewhere… who knows where? It had a green padlock icon, right?
SCRAM in detail
Initially, I intended to go into the finer details of SCRAM in this article as well. However, after some researching I didn’t find any diagrams or explanations of SCRAM that suited how I was trying to describe it. So, I made my own. However, it’s now a bit too dense and technical to suit the current article. Instead, I’ll post that separately, including further detail into its use of channel binding, and provide a link once it’s available. In the meantime, Jonathan S. Katz has one of the first articles I read on the subject, in relation to SCRAM, Postgres and pgBouncer.
With that set to one side, let’s instead comment on its weaknesses.
SCRAM’s problems
SCRAM does a lot to protect the password as well as to ensure that both parties have some common prior knowledge. However, there are some potential shortcomings:
- The server must provide a salt and iteration count for a requested user. If not handled well, this could reveal the existence/non-existence of particular users.
- The client must store the password, because the salt and iteration count is determined by the server. Unless, of course, these are guaranteed not to change without setting a new password, in which case the salted version, or client and server keys, could be stored instead.
- The password in its salted or key forms can still be brute forced or subject to dictionary attacks. The password strength, salt length and iteration count are the defences against this, which will weaken over time as machines get faster.
- MITM style attacks are not completely mitigated, because while a MITM never gets a look at any passwords, hashes or keys, it can pass the messages between client and server and then hijack whatever results from a successful authentication, which is usually an application session token, as mentioned in the previous section.
- The above all assume that SCRAM is the only authentication method supported by the client. If it also supports HTTP Basic Authentication or something similar, then a phishing site can just solicit details that way instead.
SCRAM is definitely an improvement on many widely used credential-proving mechanisms, but we can still do better.
Channel binding
The layers of security that we’ve been talking about here are usually de-coupled from each other. This is useful. It’s good engineering. Build things in layers and you can make more advanced things without changing all that lays underneath.
However, this means that authentication technologies don’t know much about the underlying layers of security. Is the TLS session really secure? Is the user on an open WiFi network? Is the user’s DNS provider trustworthy? The authentication layer seldom knows these things.
With channel binding, the application performing authentication pays closer attention to the security provided at some layer beneath it. In this case, TLS.
The idea
The basic principle behind channel binding is that the activity being performed at an upper level is bound to some lower level. If we think about networking in general, our OSI model layer 7 (application) sessions are often established over a layer 5 session such as TCP. But if there’s a proxy server between a client and server, then the application session may very well take place over more than one TCP session (client to proxy, then proxy to backend server). Layers of engineering at its finest.
If we focus in on TLS, which sits in OSI model layer 6, the same principles apply. The application session might take place over a single TLS session, but it doesn’t have to, and neither users nor servers might be very good at checking.
With channel binding, however, we use some data from the lower level communication channel - in this case a TLS session - in order to ensure that our higher level activity must take place over that channel and that channel alone. It avoids a MITM. If the TLS session is terminated, the authentication process must also be terminable at that location, or if the authenticating application is running in a backend server, behind a frontend that accelerates TLS, then the accelerator will need to pass the relevant channel binding data upstream to the app for correct handling (and hope that other provisions are made to avoid a MITM between the frontend and backend).
In practice
Channel binding is detailed in RFC 5056 and SCRAM accommodates this as an optional feature as described in RFC 5082. Microsoft has also introduced channel binding support as an extension to LDAP. Channel binding methods for TLS are defined in RFC 5929. Using these sources and a few more along the way, I’ll unpack the way this is intended to work, using SCRAM with TLS channel binding as an example.
At its simplest, a Channel Binding Token (CBT) is generated from some components of the underlying TLS session. This token is included in the upper authentication step. This can be checked to ensure that the CBT indeed relates to the specific channel that they are using, and therefore authentication (or some other exchange) can proceed safely. The application and/or client must have access to sufficient information from the TLS layer, in order to verify the CBT, hence support is not automatic. We’ll see later that it tends to be the server that performs this verification.

We see in the above diagram how the introduction of the CBT defeats the attack. If variants of SCRAM that include channel binding are used (denoted by “PLUS” in their name), then the authentication will fail even before 2FA is performed or the app token is sent. Of course, a CBT could be used for either of those as well, but there is little point in using it across multiple layers, as if it is somehow defeated, it will be likely be useless across them all.
Channel binding in TLSv1.2
TLS version 1.2 is the oldest version of TLS still considered safe enough for use at the time of writing. In this version, there are three registered channel binding methods that can be used, per RFC 5929:
tls-unique: This method uses the firstTLS Finishedmessage sent in a TLS connection as the CBT. In a normal, full TLSv1.2 session establishment, this is sent by the client. However, for session resumption, this message is sent by the server. As such, the CBT is not consistent over a session if that session is resumed. Rather, the CBT binds to the channel’s individual connection. If renegotiations or resumptions occur, the binding may fall out of sync and fail, which might actually be a good thing.tls-server-end-point: In this method, the server’s certificate is hashed and used as the CBT. The client can provide this CBT back to the server, whereupon the server can determine if matches its own certificate. If it doesn’t, then a different certificate, likely from a MITM, was presented to the client.tls-unique-for-telnet: This is a special method that assumes aStartTLScommand is introduced into Telnet software and bases the channel bonding token on theTLS Finishedmessage, similar totls-unique.
For tls-server-end-point, the CBT will not change between sessions unless the server certificate also changes, whereas for tls-unique, every connection, even with the same server and certificate, should be different. For environments where the server certificate is known, certificate pinning for the client might be preferable over the effort of supporting channel binding. Indeed, SCRAM’s specification states that if channel binding is supported, then tls-unique must be amongst the supported modes. The client’s preference on channel binding mode must also be honoured.
Channel binding in TLSv1.3
Channel binding features were omitted from TLSv1.3 initially, which poses some problems as we’ll see later.
However, a new mode, dubbed tls-exporter has been proposed. This mode uses an exporter to produce Exported Keying Material (EKM) based on a TLS session’s master secret as per RFC 5705 and the label EXPORTER-Channel-Binding. The exported value is unique to the session as it is based on the master secret, but does not aid in determining the master secret. It’s impossible to distinguish a random sequence of bytes from a tls-exporter CBT of the same length. TLS renegotiation must not be allowed when this binding mode is in use.
Given that earlier TLS versions also have master secrets, one might be tempted to use tls-exporter with them as well. However, RFC 5705 section 5 gives some hints as to why this is a bad idea:
With certain TLS cipher suites, the TLS master secret is not necessarily unique to a single TLS session. In particular, with RSA key exchange, a malicious party acting as TLS server in one session and as TLS client in another session can cause those two sessions to have the same TLS master secret.
That’s exactly the kind of phishing scenario we’re discussing in this article. One could avoid this issue with careful selection of supported ciphers, such as requiring DHe or ECDHe. However, TLSv1.3 drops support for methods that would be vulnerable to the above-quoted issue, therefore v1.3 is a safer bet without having to worry about configuration correctness (at least with respect to the master secret’s uniqueness).
To that end, a draft addressing TLSv1.3’s channel bindings proposes to update SCRAM’s default channel binding to use tls-exporter for TLSv1.3 and above, leaving TLSv1.2 alone.
Channel binding in action
I looked online for examples of how a CBT works with SCRAM, and didn’t find any good ones. So then I thought I’d see if PostgreSQL, which supports SCRAM, has reasonably easy to follow source code. However, I was surprised to see that it doesn’t support the tls-unique method, only tls-server-end-point. On the surface, this seems like a mistake, because SCRAM’s RFC has a clear message about support:
Servers MUST implement the “tls-unique” [RFC5929] channel binding type, if they implement any channel binding.
In actual fact, TLSv1.3 is the problem, because up to now channel bindings for it, and the affect that has on SCRAM are still only in draft, so how is PostgreSQL to support channel bindings safely and reliably? They also highlight another legitimate issue: not all TLS libraries expose the necessary information, or do so consistently.
To set us on the path towards demystification, I created a piece of sample code that demonstrates how tls-unique channel binding interacts with the SCRAM process. It’s not meant to be something that can be built upon as an authentication library - it’s more like a code version of the diagrams you saw earlier. When I wrote it, I was focused on tls-unique, although now, I feel that a tls-exporter version would also be a good idea.
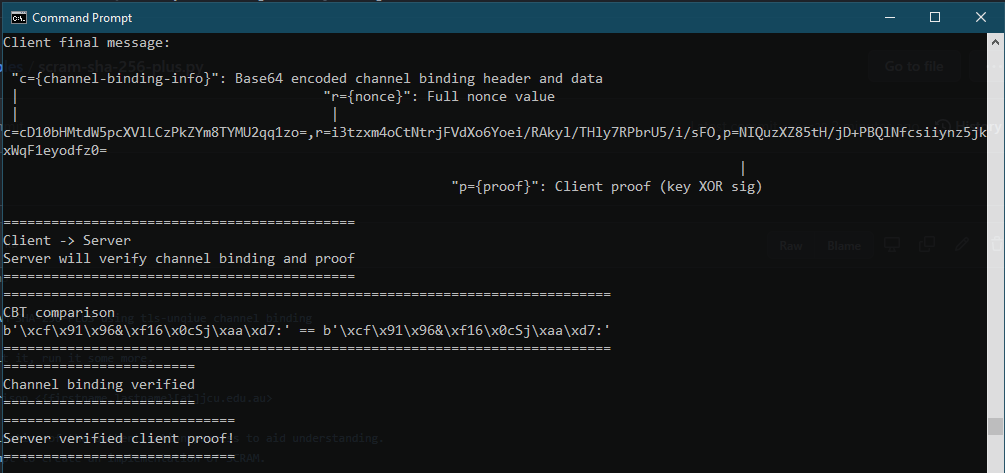
Feedback or contributions relating to this example are welcomed at its GitHub repository.
Drawbacks
In SCRAM’s PLUS variants, the client offers up the CBT in its final message to the server. That means the server can verify that the client is using the TLS session it’s expecting and that no MITM is present. But what if the server doesn’t check? Can the client know that the server is using the correct TLS session? Unfortunately, the answer is no. The client has offered up the CBT and this is a symmetric piece of data. Thus, once the server has it, regardless of whether it checks it, it could return the same data back to the client, which is of no benefit to confidentiality or integrity.
A potential fix for this would be to derive separate channel binding tokens on each side, using a key derivation function based upon the tls-unique data. By doing so, both client and server can prove knowledge of the specific TLS session without disclosing the tls-unique data itself. The tls-exporter CBT that has been proposed has the same issue, although could easily accommodate different exported material on each side of the session.
Why doesn’t SCRAM do this? I honestly do not know. Do other applications with channel binding do it or something similar? I also do not know at the time of writing. To me, it seems strange to once again make a security feature work only in a single direction. I can understand why client certificates are troublesome, but mutual CBT verification seems much simpler by comparison.
Why aren’t we using this already?
We’ve seen examples of how TLS and MFA don’t fully protect us from MITM phishing attacks, and also how TLS channel binding can help with that.
So where’s the uptake? For clients and server-side applications to support it, there needs to be access to the required data, such as the tls-unique data object or exported material for tls-exporter. The rest requires the authentication mechanisms to use that data, hopefully in a standardised way such as SCRAM-PLUS.
Server-wide, there was an attempt to introduce channel binding awareness into Nginx so that applications and CBT-aware clients could then use it. It seems that the tls-server-end-point method was viewed was preferred as that requires no development in nginx. While that’s true, I highlighted previously that the CBT may be the same across multiple sessions with the same server and that in the case of SCRAM, tls-unique must be supported if channel binding is supported at all and we’ve seen that TLSv1.3 has thrown a spanner into that as well. Microsoft has worked on it, with IIS and Edge having some support. But in general, I haven’t seen it in use, certainly not with any web applications I’ve worked with, although it’s quite possible I’m just not doing enough work in that area to notice. Have you seen CBTs used anywhere?
It may be that another approach will ultimately be preferred, and that may be token binding. If you’ve ever used client certificates for mutual TLS (2-way certificate-based authentication), you have probably found them cumbersome and tricky to work with. Token binding builds upon the idea of self-signed client certificates that are bound to interactions with specific servers or applications, so that nobody jumps into the middle of the exchange in a future conversation to steals a bearer token. Drafts exist for this approach, including proposals for OAuth 2.0, and a number of big hitters back the idea, but support seems to be limited as of yet. It relies on extra interactions with the TLS layer, just like channel binding, so is subject to many of the same implementation challenges.
In short, if channel binding can be used to bind an authentication process to a TLS channel, token binding does something similar with the resultant application session token.
Where next?
In this article I’ve shown how channel binding deals with some of the shortcomings of existing authentication methods, even over the apparent security of TLS connections. I’ve also talked about how it requires extra effort to support, and that uptake isn’t there, with alternatives such as token binding also vying to be a widely adopted solution.
There’s a lot of uncovered ground that hopefully I can visit in the future. This ranges from analytics to detect unusual login attempts that may signify a phishing attack, through to stronger MFA techniques that can also defeat a MITM. I’m particularly intereted to look at what web browsers can do to prevent phishing, particularly as HTTP’s weaker authentication mechanims are still readily available, without warning, most of the time.
But for now, please let me know: Is channel binding a feature worth supporting? Do you think the SCRAM implementation could be improved by allowing the client to verify the CBT as well? Would you prefer to see token binding or some other alternative be more widely adopted instead?
Acknowledgements
This article was inspired by a presentation titled “Re-thinking authentication” by Marcus Guan from Okta, hosted by (ISC)2’s Singapore Chapter. If you’re a local cybersecurity professional and not a member of (ISC)2 or the SG chapter, I’d recommend it.
Additional links
Whenever I’m in doubt about how TLS works, I like to refer to ulfheim.net’s TLSv1.2 and TLSv1.3 illustrations. If you’ve never seen them before, go check them out!
GSS-API also supports channel binding (and SCRAM). If RFCs are your thing, you might want to start with RFC 5554 and work from there, or take a look at Oracle’s GSS-API programming guide.